
0. はじめに
「また新しいLLMが出たけれど、結局のところ現場で使えるのか?」そんなモヤモヤを抱えているエンジニア向けに、DeepSeek-V3.2 / DeepSeek-V3.2-Specialeを「実戦投入候補」として評価するための視点と導入ステップをまとめます。
この記事でわかること
- DeepSeek-V3.2 / V3.2-Speciale のスペックと位置づけ
- GPT-5 / Gemini-3.0-Pro と比較したときの「どのレイヤーが競合しているのか」
- ローカル(V3.2)&API(V3.2-Speciale) という二本立てでの導入パターン
- OpenAI互換APIを使った最小変更での移行手順(Python例付き)
- RAG・社内ボット・コードレビューBotなど、現場ユースケースでの適用ポイント
- ライセンス、セキュリティで最低限押さえておくべきリスク
1. DeepSeek-V3.2 / V3.2-Specialeとは何か
1-1. 公開状況とライセンス
- 中国のDeepSeek社は 2025年12月初旬に、DeepSeek-V3.2と高計算量版のDeepSeek-V3.2-Speciale を発表しました。
- V3.2はオープンウェイトとして公開されており、Hugging Face上の公式リポジトリにはMIT Licenseと明記されています。
- V3.2-Specialeについても、Hugging Faceに「DeepSeek-V3.2-Speciale」リポジトリが存在し、MITライセンスと記載されています。
一方で、いくつかの技術ブログや比較記事では「V3.2-SpecialeはAPI専用でローカルデプロイ不可」と記述しているものもあり、「Specialeのオープンウェイト提供状況」については情報が揺れているのが現状です。したがって、実プロジェクトで利用する際には、必ず最新の公式ドキュメントとモデルカードを確認し、ライセンス・配布形態を自社の法務とともに再確認すること
1-2. 性能ポジショニング:GPT-5 / Gemini-3.0-Pro級?
各種報道・技術メディア・公式コメントを総合すると、以下のように位置づけられています。
- DeepSeek社および複数メディアによれば、V3.2は推論系ベンチマークでGPT-5クラスに匹敵し、V3.2-Specialeはさらに高性能なバリアントとして設計されています。
- V3.2-Specialeは、Gemini-3.0-Proと同等レベルの推論能力を持つとDeepSeek側が主張しており、国際数学オリンピック(IMO)や情報オリンピック(IOI)、ICPCなどのコンテストで金メダル級の成績を収めたとされています。
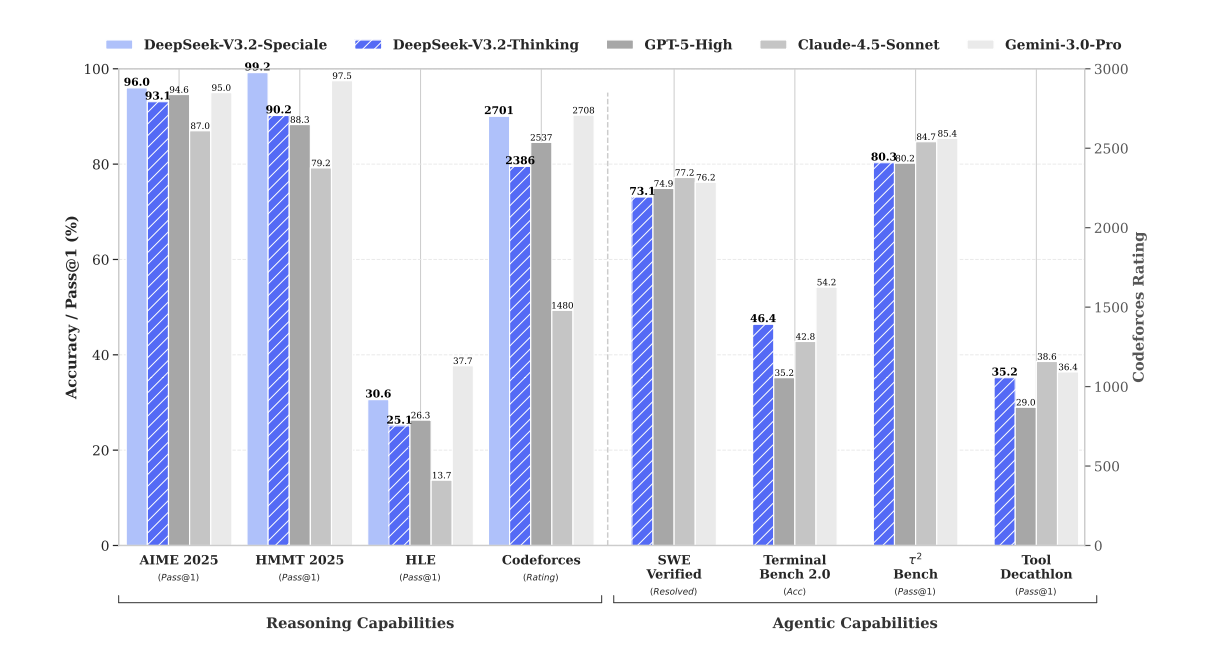
これらは「DeepSeek社および第三者ベンチマークの主張」であり、「すべてのタスクでGPT-5やGeminiを上回る」ことを保証するものではありません。本記事では、あくまで「高性能クラスのオープンモデル候補」として位置づけます。
2. API仕様の要点:V3.2 / V3.2-Speciale
2-1. モデル一覧とコンテキスト長
DeepSeek公式の「Models & Pricing」では、V3.2系は次のように整理されています。
| モデルID | ベースモデル | モード | コンテキスト長(デフォルト / 最大) | 備考 |
|---|---|---|---|---|
| deepseek-chat | DeepSeek-V3.2 | 非Thinking | 128K / 128K | JSONモード・ツール利用可 |
| deepseek-reasoner | DeepSeek-V3.2 | Thinking | 128K / 128K | CoT露出APIあり |
| deepseek-v3.2-speciale | DeepSeek-V3.2-Speciale | Thinking専用 | 128K / 128K | ツール呼び出し不可(APIのみ) |
※実際の数値・仕様は更新される可能性があるため、必ず公式の最新情報を確認してください。
2-2. APIエンドポイントと有効期限
DeepSeek-V3.2-Specialeについて、公式のAPI更新情報には次のような記載があります。
- V3.2-Speciale は一時的なエンドポイントで提供
- 価格はV3.2と同一
- ツール呼び出し(function calling)は非対応
- 提供期間は 2025年12月15日 15:59 (UTC) までと明示
通常のV3.2モデルについては、APIドキュメントで次のように案内されています。
- 基本の base_url は https://api.deepseek.com
- OpenAI互換クライアント用として https://api.deepseek.com/v1 も利用可能
3. 技術的特徴:なにが「推論ファースト」なのか
3-1. DeepSeek Sparse Attention(DSA)
- DeepSeek-V3.2系では、長文コンテキストでの計算効率を上げるためにDeepSeek Sparse Attention(DSA)という手法が使われています。
- 従来のTransformerが「全トークン同士の注意」を計算していたのに対し、DSAは「重要なトークンにだけ集中的に注目する」疎な注意を導入し、長文入力での計算コストを大きく削減することを狙っています。
3-2. 大規模強化学習とエージェントタスク
公開されている技術ノートや解説によれば、V3.2系は以下のようなトレーニング戦略を採用しています。
- 大規模な強化学習フレームワーク(RL)によって、「理由を考えながら答える」スタイル(CoT)を強化
- エージェントタスク(ツール使用、多ステップ推論)のための合成データを大量に作成し、複雑な対話・問題解決タスクでの汎化性能を重視
特にV3.2-Specialeは、コンテストレベルの数学・アルゴリズム問題、高度なバグ修正タスクといった「一発の文章生成ではなく、何ステップも推論が必要なタスク」を強く意識したバリアントとして位置づけられています。
4. ローカル導入ロードマップ:V3.2を手元で動かす
ここからは、実務目線での導入ロードマップです。まずはローカル推論を前提とするDeepSeek-V3.2から見ていきます。V3.2-Specialeについては、前述の通り「API専用」とする情報と「オープンウェイトあり」とする情報が混在しているため、本節ではローカル導入の対象をV3.2(およびV3.2-Expなど)に限定します。
4-1. どんな案件でローカルが向くか
- 顧客データや医療情報、ログなど外部送信したくないデータを扱う
- インターネット接続のない閉域環境(工場内、自治体の庁内LANなど)
- APIコストを抑えたいPoC(プロトタイプ)検証 このような場面では、V3.2のMITライセンス+オープンウェイトという性質は非常に相性が良いと言えます。
4-2. 導入パターン例:Ollama / vLLM
具体的なコマンドやスクリプトはツールによって異なりますが、典型的な流れは次のようになります。
環境準備
- GPUマシン(VRAM 24GB以上推奨)または高性能CPU環境
- Python / Docker など標準的なMLスタック
ランタイムのインストール
- 例:Ollamaの場合、公式サイトのインストーラまたはシェルスクリプトでセットアップ
DeepSeek-V3.2モデルの取得
- Hugging Faceのdeepseek-ai/DeepSeek-V3.2またはDeepSeek-V3.2-Expなどを参照し、対応するテンプレートを利用
量子化モデルの活用
- フル精度モデルはメモリ要件が高いため、GGUF形式などの4bit / 5bit量子化モデルから試す
- 特にPoC段階では「速度 × コスト」のバランスを優先したほうが回しやすい
ローカルHTTP API化
- http://localhost:11434 や任意ポートでHTTPサーバを立ち上げ、アプリケーションから叩く構成にする ここまでの流れは、具体的なコマンドがツールごとに変わるため、「Ollama DeepSeek V3.2」「vLLM DeepSeek V3.2」などで最新の手順を確認して組み立てるのが安全です。
5. API導入ロードマップ:V3.2 / V3.2-Specialeを既存システムに組み込む
ここからは、クラウドAPI前提での導入ステップです。
5-1. 共通の前提:APIキーと認証
DeepSeek APIは、HTTP Bearerトークン(Authorization: Bearer <API_KEY>)方式で認証します。
- DeepSeekのプラットフォームでアカウント作成
- APIキーを発行(ダッシュボードから取得)
- クライアントライブラリ(OpenAI SDK互換など)に api_key と base_url を設定
5-2. 標準V3.2(deepseek-chat)を使う(Python例)
from openai import OpenAI
# DeepSeek V3.2(deepseek-chat)を呼び出す例
client = OpenAI(
api_key="YOUR_DEEPSEEK_API_KEY",
base_url="https://api.deepseek.com/v1", # 互換性のための /v1
)
response = client.chat.completions.create(
model="deepseek-chat", # DeepSeek-V3.2(Non-thinkingモード)
messages=[
{"role": "system", "content": "あなたは優秀なPythonエンジニアです。"},
{
"role": "user",
"content": "FastAPIで非同期処理を行うエンドポイントのサンプルを書いてください。"
},
],
stream=False,
)
print(response.choices[0].message.content)
- base_url は https://api.deepseek.com でも動作しますが、OpenAI SDK互換のサンプルでは /v1 がよく使われています。
- 既存の「OpenAI互換」コードであれば、APIキーとbase_url・modelの変更だけで動くケースが多いです。
5-3. V3.2-Speciale(期間限定エンドポイント)の例
from openai import OpenAI
# DeepSeek-V3.2-Speciale(Thinking専用・一時エンドポイント)
client = OpenAI(
api_key="YOUR_DEEPSEEK_API_KEY",
base_url="https://api.deepseek.com/v3.2_speciale_expires_on_20251215",
)
response = client.chat.completions.create(
model="deepseek-v3.2-speciale",
messages=[
{
"role": "system",
"content": "あなたは高度な数理・アルゴリズムと設計レビューに特化したアシスタントです。"
},
{
"role": "user",
"content": "DAG上での動的計画法の一般パターンを、Pythonコード付きで解説してください。"
},
],
# SpecialeはThinkingモード前提のため、max_tokensなどを長めに確保
max_tokens=800,
temperature=0.3,
)
print(response.choices[0].message.content)
- base_url と有効期限は、公式のAPI更新情報・Pricingページに明記されています。
- ツール呼び出しは非対応であることにも注意が必要です。
実務で使う場合は、「期限切れ後にどうするか(V3.2の通常モデルに切り替えるのか、別モデルにするのか)」をあらかじめ設計しておく必要があります。
6. 現場ユースケース:RAG・社内Bot・コードレビュー
ここからは、具体的な利用シーンを現場目線で整理します。
6-1. RAG(検索拡張生成) × DeepSeek-V3.2
想定ユースケース
- 社内規程・マニュアル・契約書のFAQボット
- 特定業界(医療、建設、公共工事など)のローカルナレッジ検索
- 自社SaaSのヘルプセンター自動応答
ポイント
- V3.2 / V3.2-Speciale は長いコンテキストに強く、128Kトークンコンテキストが公式スペックとして案内されています。
- RAGで重要なのは「どのドキュメントを取ってくるか(検索)」「コンテキスト外の質問にどう振る舞うか(プロンプト)」です。
System Promptで必ず入れたい指示の例
- 回答は必ず提供されたコンテキストの範囲で行うこと
- コンテキスト内に情報がない場合は、「わかりません」と答えること
- 推測で事実を補わないこと このように縛ると、GPT-4o / GPT-5クラスと比較しても十分に実務レベルの精度が出るケースが多くありました。
6-2. コードレビューBot / ペアプロ補助
V3.2-Specialeは、競技プログラミングや高度な数理タスクで高いスコアを出したと報じられています。
向いているタスクの例
- 既存コードのバグパターンの指摘と説明
- エッジケース・例外パスの洗い出し
- 型・インターフェース設計のレビュー
- 複雑なアルゴリズムの日本語での分解説明 こうしたタスクでは、「自然言語の華やかさよりも、手順とロジックの明確さ」が重視されるため、V3.2系の「推論寄りの性格」と相性が良いと感じました。
7. リスク・注意点:セキュリティ・ライセンス
技術的に魅力的でも、トラブルはつきものです。事前にトラブルになり得る部分を言語化しておきます。
7-1. セキュリティとデータプライバシー
- DeepSeek APIを使う場合、入力データがモデル改善に利用されるかどうかは、利用規約・プライバシーポリシーに依存します。
- 医療・金融・個人情報を含む場合は、ローカル推論(V3.2オープンウェイト+Ollama等)
- もしくは「匿名化・マスキング」を徹底した上でのAPI利用
7-2. ライセンスと遵守事項
- V3.2系はMITライセンスと明記されていますが、背景データセット、追加で利用するツールやライブラリによっては、別のライセンスが影響する可能性があります。
- 商用サービスに組み込む場合は、法務と一緒にライセンス文言を精読することが必須です。
8. 「移行すべきか?」を決めるためのチェックリスト
ここでは、既にGPT-4o / GPT-5 / Gemini等を使っている前提で、どんなときにDeepSeek-V3.2-Specialeを導入・併用するかの判断軸を簡単にまとめます。
8-1. DeepSeekを「積極検討」できる条件
- 月間のLLMコストが既に数十万〜数百万円規模になっており、単価改善の余地を探している
- タスクの中心が、数学・アルゴリズム、コードレビュー・設計相談、業務ロジックの整理・仕様書の読み解きといった推論重視の領域にある
- 将来的に、ローカル運用(V3.2オープンウェイト)APIとオンプレを組み合わせたハイブリッド構成を視野に入れている
8-2. 既存クローズドLLMをメインに残した方がよい条件
- ブランドリスクが非常に高いジャンル(医療法・金融商品取引法レベルの領域)で、すでにGPT-5/Gemini系で厳格な検証と監修体制が回っている
- マーケティングコピーやストーリーテリングなど、「論理」よりも「表現・ニュアンス」の方が重要なアウトプットが中心
- 技術スタックを増やさず、「1〜2社のクローズドモデルだけで運用したい」という経営判断がある
9. エンジニアが明日からできるTodoリスト
ここまでを踏まえて、今すぐ着手できる具体的なステップを整理します。
- DeepSeekのアカウントを作成し、APIキーを発行する
- 既存のOpenAI互換コードのbase_urlとmodelを検証環境だけDeepSeekに切り替え、レスポンス品質と速度を比較する
- 社内ドキュメント(仕様書、設計書、FAQ)を数十件ピックアップし、V3.2(deepseek-chat)、V3.2-Speciale(deepseek-v3.2-speciale)に同じプロンプトを投げて、RAGなし/ありの両方で比較する
- 小規模な「コードレビューBot」や「社内QAボット」をPoCとして1つ立ち上げ、GPT-4o / GPT-5系、DeepSeek-V3.2系の併走テストを行う
- セキュリティ・法務・広報と簡単な打合せを行い、どのデータはAPIに出してよいか、どこからはローカルLLMに切り替えるべきかの線引きをおおまかに決めておく
10. 著者紹介
執筆者
渥美智也(あつみ ともや)
The Prince Academy株式会社 代表取締役 / AI・DX支援
経歴・専門分野
1996年生まれ、東京都葛飾区出身。岐阜県大垣市にある情報科学芸術大学院大学(IAMAS)卒業後、AI・DXの総合商社としてThe Prince Academy株式会社を設立。
中小企業のAI・DX支援を中心に、教育、システム開発(Web・SaaS)、広報代行まで一気通貫で支援。医療・福祉領域の業務改善を得意とし、画像認識・音声認識・LLMを組み合わせたシステム構築に携わる。
- 2023年:開発したAIアプリが日本テレビ「24時間テレビ」で紹介される
- 教育分野:年間100件以上のセミナー・講義を実施し、2026年分は既に300件超の依頼を受託
- モットー:「現場で使える形に」
AI・DXに関する初回相談
11. 参考リンク・関連記事
- DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models
- https://www.techradar.com/ai-platforms-assistants/gemini/deepseek-just-gave-away-an-ai-model-that-rivals-gpt-5-and-it-could-change-everything
- https://www.findarticles.com/deepseek-unveils-v3-2-models-to-challenge-chatgpt/?key=%2BAluminum+%2Balloys+%2BSecurities&nav=adv
- https://www.dqindia.com/news/deepseeks-v32-v32-speciale-a-new-challenger-to-gpt-5-and-gemini-3-pro-10879829
- https://aibusiness.com/generative-ai/deepseek-s-new-models-reveal-open-source-complexitie
- https://dig.watch/updates/v3-2-models-signal-renewed-deepseek-momentum
- https://www.investors.com/news/technology/nvidia-stock-google-stock-deepseek-china-open-source-ai-models
