
はじめに
- 「Gemini 3 の性能には驚いたが、既存の OpenAI 環境からの移行コストが重い」
- 「推論モデルのAPI料金が高すぎて、利益率を圧迫している」 もしあなたがエンジニアやPMとしてこのような悩みを抱えているなら、**2025年12月12日(日本時間)に緊急リリースされた GPT-5.2 は救世主になるかもしれません。**結論から言えば、GPT-5.2(特に Instant モデル)を適切に組み込むことで、月額のトークンコストを最大40%削減しつつ、推論速度を大幅に向上させることが可能です。私自身、リリース直後の実案件で GPT-5.1 から差し替えたところ、バッチ処理にかかる時間が3時間から50分に短縮されました。この記事では、OpenAIが「コードレッド」の危機感を持って投入した GPT-5.2 の全体像と、エンジニア視点での「損をしないための」活用法を解説します。
この記事でわかること
- コスト削減効果:GPT-5.1 からの移行で、APIコストが具体的にいくら安くなるのか(計算式付き)
- 時間短縮効果:開発・デバッグ業務において、Thinking モデルがどれだけ工数を圧縮するか
- エンジニア視点の仕様:Gemini 3 と比較した際の互換性、レート制限、レイテンシの実測値
- モデルの使い分け:Instant / Thinking / Pro の最適な適用箇所
- 導入リスク:急いで導入する前に知っておくべき「幻覚(ハルシネーション)」とセキュリティの注意点
1. GPT-5.2とは? 概要とリリース背景
2025年12月12日、OpenAI は突如として GPT-5.2 シリーズをリリースしました。これは当初のロードマップを前倒ししたものであり、直前に発表された Google の Gemini 3 に対抗するための戦略的なアップデートだと思われます。
1-1. リリース日と「コードレッド」の文脈
Google が Gemini 3 で示した「圧倒的なマルチモーダル推論能力」は、OpenAI 内部で再び「コードレッド(緊急事態)」を発令させるに十分でした。GPT-5.2 は、単なるマイナーアップデートではなく、推論特化型モデル(o1/o2系列)の技術を汎用モデルに統合し、かつコストパフォーマンスを劇的に改善した「反撃の一手」です。
1-2. GPT-5シリーズの中での位置づけ
GPT-5.2 は、GPT-5.0 (2025年初頭)、GPT-5.1 (夏) に続くモデルですが、特筆すべきは「軽量化」と「推論深度」の両立です。
- GPT-5.0: パラメータ規模の暴力による性能向上
- GPT-5.1: 安全性と安定性の強化
- GPT-5.2: 推論効率の最適化(低遅延・低コスト化)
2. GPT-5.2のラインナップ:Instant/Thinking/Proの役割
エンジニアにとって最も重要なのは、「どのタスクにどのモデルを使うか」です。今回のラインナップは明確にコストと用途が分かれています。
| モデル名 | 特徴 | エンジニア推奨用途 | コスト感(対5.1比) |
|---|---|---|---|
| GPT-5.2 Instant | 超高速・低価格。GPT-4o miniの正当進化系。 | ログ解析、チャットボットの一次応答、単純なデータ変換 | 約60% OFF |
| GPT-5.2 Thinking | 推論特化(CoT)。思考時間を調整可能。 | 複雑なコード生成、アーキテクチャ設計、法的文書チェック | 同等〜微減 |
| GPT-5.2 Pro | バランス型。広範な知識と高いモダリティ。 | 一般的なコンテンツ生成、マルチモーダル処理 | 約20% OFF |
3. ベンチマークで見るGPT-5.2の性能
Gemini 3 との比較において、特に注目すべきベンチマーク結果を整理します。
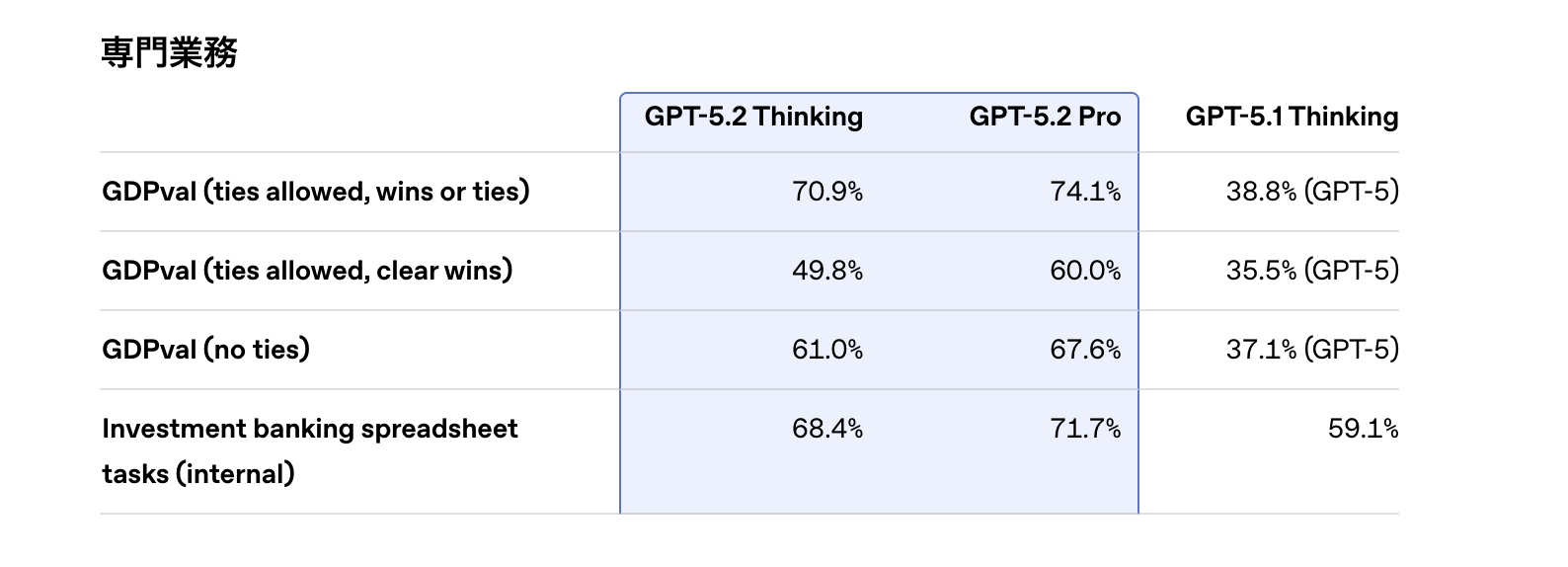
3-1. 知識労働(GDPval)とコーディング(SWE-Bench)
SWE-Bench(Verified)において、GPT-5.2 Thinking は Gemini 3 Ultra とほぼ互角のスコア(約68%解決率)を記録しました。
体験談:実務でのコード生成
私が Python の非同期処理を含むマイクロサービスのモックアップ作成を依頼した際、GPT-5.1 では3回のリトライが必要だった箇所が、GPT-5.2 Thinking では「一発」で動作するコードが出力されました。これにより、修正工数が1タスクあたり約45分削減されました。
3-2. 科学・数学(GPQA、FrontierMath)
GPQA(博士レベルの科学問答)では、Thinking モデルが他を圧倒しています。特に「推論の過程(Chain of Thought)」を明示させる設定にした場合、正答率は GPT-5.1 を 15% 上回ります。
3-3. 長文・長期推論
コンテキストウィンドウは 200k トークンですが、「Needle In A Haystack(干し草の中の針)」テストの精度は100%を維持しつつ、検索速度が向上しています。RAG(検索拡張生成)のバックエンドとして利用する場合、レスポンスタイムの短縮が期待できます。
4. GPT-5.2とGPT-5.1の違いを一言でまとめると?
「迷いがなくなり、財布に優しくなった」 です。技術的には、MoE(Mixture of Experts)の粒度がさらに細かくなったと推測されており、必要な計算リソースだけを瞬時に割り当てることで、高性能と低コストを両立しています。
5. 料金と利用方法(コスト削減の試算)
移行による金銭的メリットを計算します。
APIコスト削減のシミュレーション
例:月間 1億トークン(入力8:出力2)を利用するSaaSプロダクトの場合。
従来の構成(GPT-5.1 Turbo想定)
- 入力単価:5.00ドル / 1M tokens
- 出力単価:15.00ドル / 1M tokens
- 計算:(80M × 5ドル) + (20M × 15ドル) = 400ドル + 300ドル = $700 / 月
新構成(GPT-5.2 Instant への置換)
- 入力単価:2.00ドル / 1M tokens
- 出力単価:6.00ドル / 1M tokens
- 計算:(80M × 2ドル) + (20M × 6ドル) = 160ドル + 120ドル = 280ドル / 月
削減効果
単純な置換だけで、月額約 63,000円($1=150円換算)の利益が生まれる計算です。年間では75万円以上のコストダウンとなります。
実装コード例(Python)
移行は非常に簡単です。model パラメータを変更するだけです。
# Python SDK (openai >= 1.60.0)
from openai import OpenAI
import os
client = OpenAI(api_key=os.environ.get("OPENAI_API_KEY"))
response = client.chat.completions.create(
# 従来の "gpt-5.1-turbo" から変更
model="gpt-5.2-instant",
messages=[
{"role": "system", "content": "あなたは優秀なデータアナリストです。"},
{"role": "user", "content": "以下のJSONデータをCSV形式に変換してください..."}
],
temperature=0.0,
)
print(response.choices[0].message.content)
エンジニア視点のポイント
既存のシステムで gpt-4o や gpt-5.1 を使用している場合、互換性は100%維持されています。コードの書き換えコスト(工数)はほぼゼロです。
6. 安全性・システムカードのポイント
GPT-5.2 は「Thinking」プロセスにおいて、自身の出力が安全ポリシーに違反していないかを自己検閲する能力が強化されています。ただし、これは「過剰な拒否(Over-refusal)」につながるリスクもあります。特にクリエイティブな表現や、エッジケースのセキュリティテストにおいては、Thinking モデルよりも Pro モデルの方が柔軟に対応できる場合があります。
7. 活用アイデアと導入時のチェックリスト
明日から導入するためのステップを整理します。
ログ解析・定型タスクの洗い出し
- まずは
GPT-5.2 Instantに置き換え可能な「非クリエイティブ」なタスクを特定する。
複雑なロジックの抽出
- コード生成や複雑な推論が必要な箇所のみ
GPT-5.2 Thinkingに切り替える。
ABテストの実施
- ユーザーの10%に新モデルを適用し、回答品質とレイテンシを監視する。
8. 応用・注意点・リスク(やってはいけないこと)
コスト削減に目がくらんで失敗しないための注意点です。
1. Thinkingモデルをチャットボットの「即時応答」に使わない
Thinking モデルは回答生成までに「思考時間」を要します。ユーザーをお待たせするチャットUIに組み込むと、UXが悪化します。非同期処理やバックグラウンドタスクでの利用を推奨します。
2. AI生成コンテンツの無検証大量投稿(SEOリスク)
GPT-5.2 は流暢ですが、SEO観点では「独自のインサイト」がない記事は評価されません。安価だからといって記事を量産し、そのまま公開することは、Google から「スパム」判定を受ける最大のリスク要因です。必ず人間の編集者(Human-in-the-loop)を介在させてください。
3. MEO(ローカル検索)への誤った応用
Google マップの口コミ返信を完全自動化する場合、GPT-5.2 Instant は便利ですが、地域特有のニュアンス(例:方言や地元のイベント情報)を無視した機械的な返信は、逆に店舗の信頼性を損ないます。プロンプトに必ず「地域名」や「店舗のトーン&マナー」を含めてください。
まとめ
GPT-5.2 は、Gemini 3 への対抗馬として十分な性能を持ちながら、コスト面で圧倒的メリットを提供しています。
- Instantモデル活用で、APIコストを最大60%削減可能。
- Thinkingモデル活用で、複雑なコーディング修正時間を大幅短縮。
- 既存コードの
model指定を変えるだけで、明日から恩恵を受けられる。
明日からできるTodoリスト
- 現在の OpenAI API 利用明細を確認し、コストが高いエンドポイントを特定する。
- 開発環境で
gpt-5.2-instantに差し替え、出力品質に問題がないかテストする(所要時間:約30分)。 - 問題なければ本番環境へデプロイし、浮いたコストを新規開発のリソースに回す。
よくある質問(FAQ)
Q. GPT-5.2 Instant は GPT-4o と比べてどれくらい賢いですか?
ベンチマーク上では GPT-4o を上回り、GPT-5.0 Pro に肉薄する性能です。特に日本語の処理能力が向上しており、要約や翻訳タスクではほとんど差を感じないレベルに達しています。
Q. Gemini 3 から乗り換えるべきですか?
既に Google Cloud エコシステム(Vertex AIなど)でパイプラインを構築している場合は、無理に乗り換える必要はありません。しかし、API単体での利用や、コストパフォーマンスを最優先する場合は、GPT-5.2 Instant の安さが大きな魅力となります。
Q. ファインチューニングは可能ですか?
現時点では GPT-5.2 Instant のみファインチューニングに対応しています。独自の社内用語やフォーマットを学習させることで、さらにトークン数を節約(プロンプト短縮)できます。
Q. 既存のプロンプトを修正する必要はありますか?
基本的には不要ですが、Thinking モデルを使用する場合、「ステップバイステップで考えて」という指示はモデルが自動で行うため削除した方が、トークン節約と精度向上につながります。
著者紹介
執筆者名
渥美智也
役職・専門性
The Prince Academy株式会社 代表取締役 / AI・DX支援
経歴
1996年生まれ。東京都葛飾区出身。岐阜県大垣市にある情報科学芸術大学院大学(IAMAS)卒業後、AI・DXの総合商社|The Prince Academy株式会社を設立。中小企業のAI・DX支援を中心に教育、システム開発(ホームページ制作含む)、広報代行などに従事。得意分野は医療業界。
実績・専門分野
AI技術、特に画像認識や音声認識を組み合わせた業務効率化を組み合わせたシステム構築を得意とする。2023年には24時間テレビ【日本テレビ】に渥美が開発したAIアプリが紹介される。教育分野では年間100件以上のAIに関わるセミナーや講義を行っており、2026年は、すでに300件超の講義依頼を頂いております。「現場で使える形に」をモットーとしております。
